AI 시대의 취약점 대응은 CVE가 붙은 뒤 움직이는 방식만으로는 늦다. 취약점은 번호가 붙기 전부터 issue, commit, PoC, write-up, 패치 흔적의 형태로 이미 움직이고 있기 때문이다.
이 글은 CVE 이후의 보안 시리즈의 첫 번째 글이다.
- 1편: CVE 이후 대응만으로는 늦다: AI 시대 취약점은 번호가 붙기 전에 움직인다
- 2편: AI Slop의 역설: 취약점을 더 잘 찾는 시대에 triage가 더 어려워지는 이유
- 3편: 보안진단은 외주 업무가 아니라 개발 공정이 된다
- 4편: 공급망 보안은 SBOM만으로 끝나지 않는다: AI 개발 도구와 자동화 연결 관리
이전에 CVE를 보안 공공재 관점에서 다룬 글, 그리고 보안진단을 코드 구조로 바꾸는 실험을 바탕으로, 이제 질문을 운영 모델 쪽으로 옮겨본다.
함께 읽을 글:
1. CVE는 여전히 필요하다
CVE는 취약점 대응의 공통 언어다.
하나의 취약점을 여러 조직이 같은 이름으로 부를 수 있게 해주고, 보안 스캐너, 패치 관리 도구, 위협 인텔리전스, 벤더 권고문을 서로 연결한다. CVE가 없다면 같은 취약점을 두고도 도구마다 다른 이름을 쓰고, 조직마다 다른 기준으로 대응하게 된다.
그래서 CVE는 단순한 번호가 아니다.
그것은 보안 생태계가 서로 대화하기 위한 좌표계다.
문제는 이 좌표계가 사라졌다는 것이 아니다. 문제는 취약점이 만들어지고, 발견되고, 재현되고, 공개되는 속도가 이 좌표계가 정리되는 속도를 앞지르기 시작했다는 점이다.
CVE가 중요하지 않아진 것이 아니다.
오히려 CVE가 너무 중요하기 때문에, 우리는 CVE가 붙기 전의 시간을 어떻게 다룰지 고민해야 한다.
2. NVD enrichment 병목은 운영 문제다
많은 조직의 취약점 대응은 대체로 이런 흐름을 전제로 한다.
CVE 공개 → NVD enrichment → 스캐너 탐지 → 우선순위 판단 → 패치 적용
여기서 enrichment는 “보강"에 가깝다. CVE가 처음 공개될 때는 취약점 설명과 참조 링크만 있는 경우가 많다. NVD enrichment는 여기에 CVSS 점수, CPE 식별자, CWE 분류처럼 도구와 운영 프로세스가 사용할 수 있는 메타데이터를 덧붙이는 과정이다.
이 보강 데이터는 단순 부가정보가 아니다. 실제 운영에서는 매우 중요하다.
- CVSS는 우선순위 판단의 출발점이 된다.
- CPE는 우리 자산과 취약점을 자동으로 연결하는 데 쓰인다.
- CWE는 취약점 패턴과 근본 원인을 분석하는 데 도움을 준다.
즉, NVD enrichment가 늦어지거나 누락되면 취약점이 존재해도 도구가 제대로 매핑하지 못할 수 있다. 보안팀은 취약점이 있다는 사실을 알더라도, 그것이 우리 자산에 해당하는지, 어느 정도 급한지, 어떤 패턴의 문제인지 판단하는 데 더 많은 수작업을 써야 한다.
이것은 단순한 데이터 품질 문제가 아니다.
취약점 관리 프로세스의 병목이다.
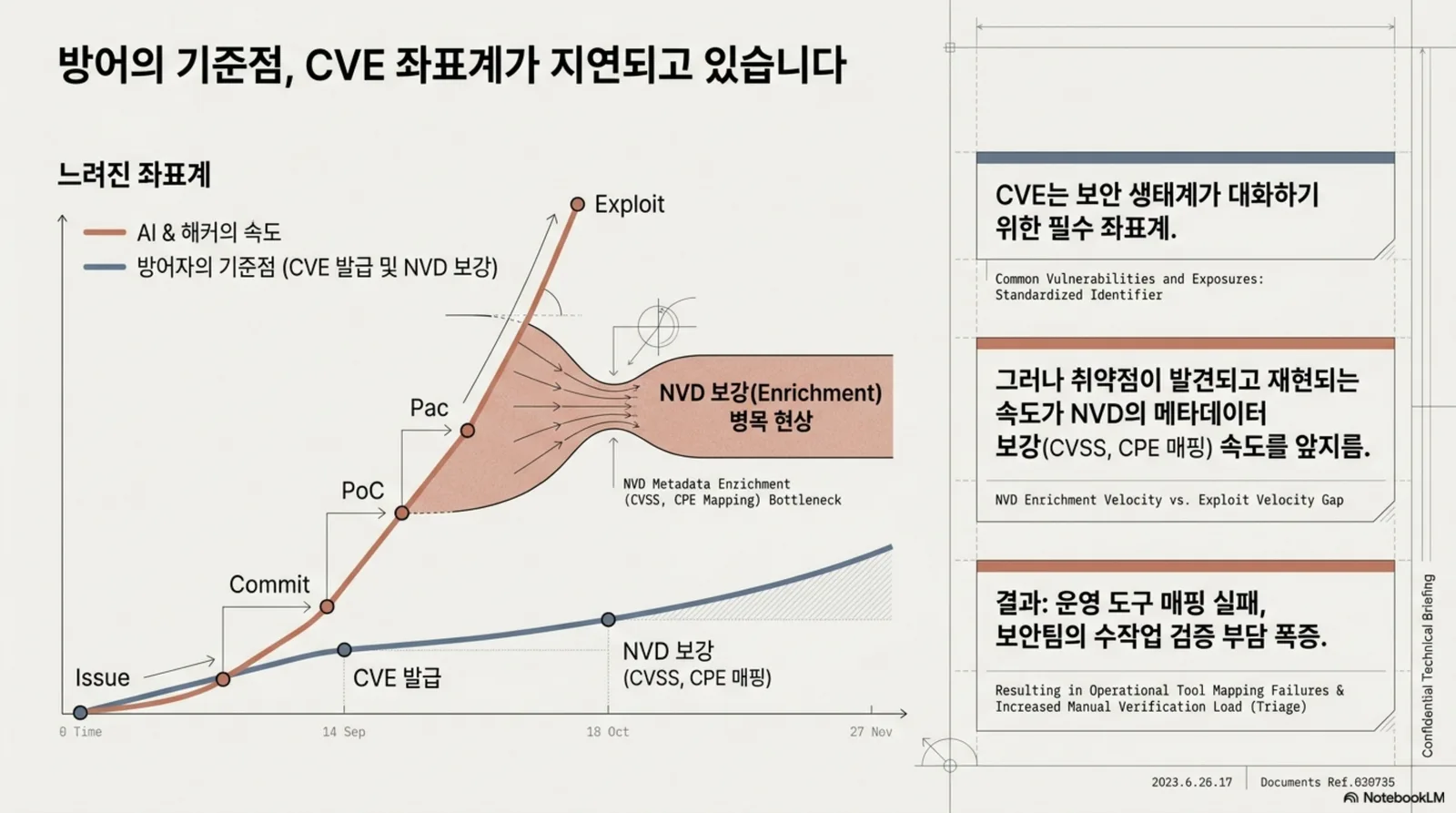
그림. CVE 좌표계는 여전히 필요하지만, NVD enrichment가 늦어지면 운영 매핑과 수작업 검증 부담이 방어자에게 넘어간다.
3. AI는 취약점 발견 비용을 낮춘다
AI 기반 취약점 연구의 핵심 변화는 “AI가 모든 것을 해킹한다”가 아니다.
더 중요한 변화는 취약점 발견과 재현의 비용이 낮아지고 있다는 점이다.
과거에는 특정 코드베이스에서 취약점을 찾고, exploit 조건을 재현하고, 패치 가능성을 검토하는 작업이 고도의 전문성과 많은 시간이 필요한 일이었다. 지금도 어려운 일인 것은 맞다. 하지만 AI agent, 코드 분석 모델, 자동화된 재현 프레임워크가 결합되면 그 비용은 점점 낮아진다.
이 변화는 이미 공개 사례로도 나타나고 있다. Calif.io의 nginx CVE-2026-27654 write-up과 califio/publications는 Claude가 취약 조건을 찾아내고, 사람이 설정 제약과 exploitability를 검증하며, 벤더와 조율해 공개한 사례를 보여준다. 더 중요한 대목은 fix commit이 공개된 같은 날, 별도의 AI 기반 commit watcher가 diff를 읽고 crashing PoC를 만들어냈다는 점이다. 패치가 공개된 뒤 공격자가 재현 가능한 exploit 힌트를 얻기까지의 시간이 줄어든 것이다.
Trail of Bits의 AI-native 운영 사례, Buttercup, trailofbits/skills도 같은 방향을 보여준다. AI는 더 이상 보고서 초안 작성 도구에만 머물지 않는다. 취약점 후보를 찾고, fuzzing 결과를 해석하고, 패치 후보를 만들고, 사람이 검증할 대상을 좁히는 공정 안으로 들어오고 있다.
비용이 낮아지면 발생하는 변화는 단순하다.
더 많은 사람이 시도한다.
더 많은 코드가 분석된다.
더 많은 취약점 후보가 나온다.
더 많은 PoC와 write-up이 만들어진다.
그중 일부는 진짜다. 일부는 과장이다. 일부는 틀렸다. 그러나 운영자는 이 모든 것을 구분해야 한다.
AI가 취약점을 더 잘 찾는 시대는, 동시에 취약점 후보를 더 많이 선별해야 하는 시대다.
4. 취약점은 번호가 붙기 전에 움직인다
현실의 취약점 공개는 항상 깔끔한 순서로 진행되지 않는다.
취약점 발견 → CVE 발급 → advisory 공개 → 패치 배포 → 운영 대응
이 순서는 이상적이다. 그러나 실제로는 다음과 같은 경로가 자주 존재한다.
- GitHub issue에서 먼저 논의된다.
- PR이나 commit에 보안 패치처럼 보이는 수정이 올라온다.
- 연구자 블로그나 SNS에 재현 조건이 먼저 공개된다.
- fuzzing walkthrough에 취약점 힌트가 포함된다.
- maintainer가 보안 버그라고 보지 않아 CVE가 붙지 않는다.
- CVE가 발급되기 전 exploit note나 PoC가 유통된다.
AI가 여기에 추가하는 것은 속도다.
AI는 commit diff를 읽고, 수정 전후 코드를 비교하고, 취약 조건을 추론하고, 재현 코드를 만드는 작업을 빠르게 보조할 수 있다. 그러면 공식 advisory가 정리되기 전에도 공격자와 연구자는 이미 충분한 힌트를 얻을 수 있다.
따라서 질문이 바뀐다.
“이 CVE가 우리에게 해당하는가?”
에서
“아직 CVE가 붙지 않은 이 신호가 우리 공급망 안에서 악용 가능한가?”
로 바뀐다.
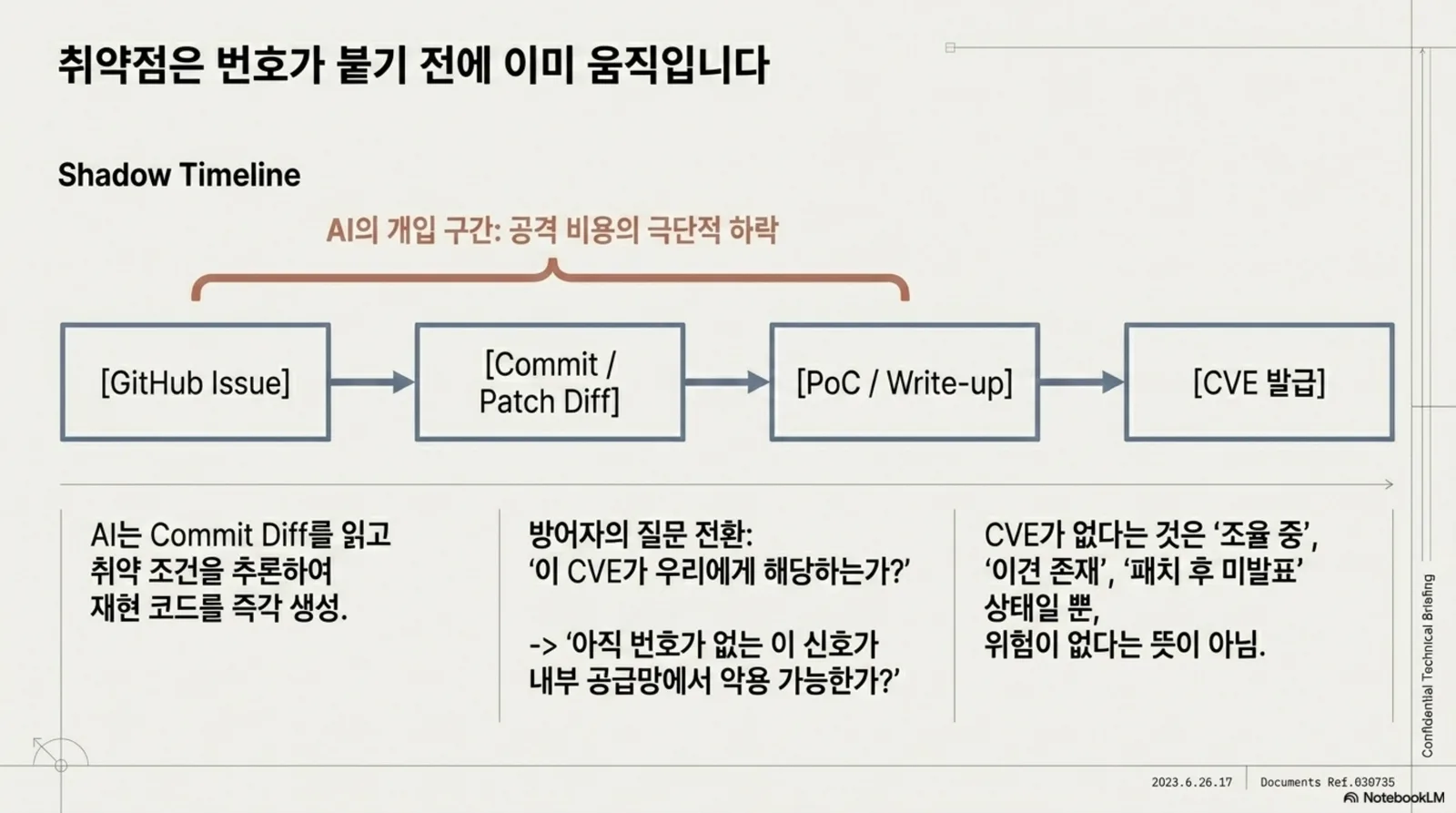
그림. issue, commit, PoC, write-up은 CVE 발급 전에 이미 움직일 수 있다. 운영자는 번호가 아니라 신호의 악용 가능성을 먼저 봐야 한다.
5. CVE 없는 취약점 후보를 무시할 수 없다
CVE가 없다는 것은 취약점이 없다는 뜻이 아니다.
CVE가 없다는 것은 단지 다음 중 하나일 수 있다.
- 아직 조율 중이다.
- maintainer가 응답하지 않았다.
- 보안 영향에 이견이 있다.
- 패치는 되었지만 advisory가 나오지 않았다.
- 취약점은 맞지만 CVE 발급 절차를 밟지 않았다.
- 연구자가 공개 채널에 먼저 기록했다.
운영 관점에서는 CVE 번호보다 중요한 질문이 있다.
우리 조직에서 쓰는가?
외부에 노출되어 있는가?
PoC나 exploit note가 있는가?
패치 commit이 존재하는가?
인증 없이 접근 가능한가?
RCE, LPE, 인증 우회, memory corruption과 관련 있는가?
이 조건을 만족한다면 CVE가 없어도 검토 대상이 될 수 있다.
물론 모든 no-CVE 항목을 동일하게 처리하면 보안팀은 금방 소모된다. 그래서 필요한 것은 더 많은 알림이 아니라 더 나은 triage다.
6. 공급망이 먼저 흔들린다
AI 기반 취약점 분석이 확산될 때 가장 먼저 압력을 받는 영역은 공급망이다.
이유는 두 가지다.
첫째, 공급망은 분석하기 쉽다.
오픈소스 라이브러리, 패키지 저장소, Docker 이미지, CI/CD 설정, 빌드 스크립트, 배포 파이프라인은 비교적 구조화되어 있다. 공개된 코드와 설정도 많다. AI가 반복적으로 분석하기 좋은 대상이다.
둘째, 공급망은 영향이 넓다.
하나의 패키지, 하나의 빌드 스크립트, 하나의 CI/CD 토큰, 하나의 자동 업데이트 경로가 여러 서비스로 확산된다. 공격자는 한 번의 성공으로 여러 시스템에 영향을 줄 수 있다.
이제 여기에 새로운 구성요소가 추가된다.
- AI IDE
- MCP 서버
- agent skill
- 자동화 커넥터
- 개발자 로컬 환경의 토큰
- 내부 문서와 코드에 연결된 RAG 파이프라인
이들은 단순한 개발 도구가 아니다. 권한을 가진 공급망 구성요소다.
따라서 공급망 보안은 더 이상 “어떤 오픈소스 버전을 쓰는가”에만 머물 수 없다. 누가 어떤 agent를 쓰는지, 그 agent가 어떤 도구를 호출하는지, 어떤 권한으로 코드를 수정하고 배포 경로에 접근하는지까지 봐야 한다.
7. 선제 대응은 모든 취약점을 먼저 찾는 것이 아니다
여기서 선제 대응을 오해하면 안 된다.
선제 대응은 세상의 모든 취약점을 먼저 찾겠다는 뜻이 아니다. 그것은 불가능하다.
선제 대응은 우리 조직의 공급망 안에서 먼저 악용될 수 있는 경로를 줄이는 것이다.
이를 위해 필요한 것은 다음과 같다.
- 중요한 공급망 자산을 먼저 정한다.
- CVE 이전 단계의 신호를 수집한다.
- 내부 사용 여부와 노출 여부를 빠르게 확인한다.
- exploitability를 기준으로 우선순위를 정한다.
- 공식 패치 전까지 임시 완화책을 만든다.
- 패치 후보를 생성하더라도 검증 게이트를 유지한다.
핵심은 속도와 책임의 균형이다.
AI를 이용해 더 빨리 찾고, 더 빨리 요약하고, 더 빨리 후보를 만들 수 있다. 그러나 어떤 조치를 적용할지, 어떤 위험을 받아들일지, 어떤 예외를 승인할지는 여전히 사람이 판단해야 한다.
8. CVE 이후의 보안
CVE 이후의 보안이라는 말은 CVE를 버리자는 뜻이 아니다.
오히려 반대다.
CVE는 여전히 필요하다. NVD도 필요하다. KEV도 필요하다. GitHub Advisory도 필요하다. 벤더 advisory도 필요하다.
다만 이제 그것들만 기다리는 방식으로는 충분하지 않다.
AI 시대의 취약점 대응은 다음과 같이 바뀌어야 한다.
CVE 이후 대응 중심
→ CVE 이전 신호 수집
→ 내부 공급망 영향도 검증
→ exploitability 기반 triage
→ 임시 완화와 패치 검증
→ 반복 가능한 운영 체계
결국 핵심은 이것이다.
AI 시대의 보안은 더 많은 취약점을 찾는 경쟁이 아니라, 더 빨리 구조화하고, 더 정확히 선별하고, 더 책임 있게 줄이는 운영 능력의 경쟁이다.
이 글의 산출물은 CVE 이전 신호를 무시하지 않고, 내부 공급망 영향도와 악용 가능성을 먼저 확인해야 한다는 운영 관점이다.
다음 글에서는 이 변화의 어두운 면을 다룬다.
AI는 좋은 취약점만 늘리지 않는다.
노이즈도 늘린다.
그리고 그 노이즈를 처리하는 비용은 결국 방어자에게 온다.
FAQ
Q1. CVE/NVD 체계가 이제 쓸모없다는 뜻인가?
아니다. CVE는 여전히 취약점 대응의 공통 언어다. 문제는 CVE와 NVD만 기다리는 방식으로는 충분하지 않다는 점이다. CVE 기반 대응은 유지하되, CVE 이전 신호를 보조 신호로 함께 봐야 한다.
Q2. CVE 없는 항목까지 보면 보안팀 일이 너무 늘어나지 않나?
맞다. 그래서 모든 no-CVE 항목을 보는 것이 아니라 내부 사용 여부, 외부 노출 여부, PoC 존재 여부, patch commit 존재 여부, RCE·LPE·인증 우회 가능성을 기준으로 선별해야 한다.
Q3. AI가 취약점 발견을 완전히 자동화했다는 뜻인가?
아니다. 현재 중요한 변화는 완전 자동화가 아니라 비용과 속도의 변화다. 취약점 후보를 찾고, 재현 조건을 좁히고, patch diff를 해석하는 일부 공정이 AI 보조 워크플로 안으로 들어오고 있다.